When Milliseconds Matter

Authors: Shayon Javadizadeh, Ishjot Walia
Background
Quota Minder is a microservice written in Elixir that enforces API Rate Limits on our third party integrators and internal applications. It is built with knowledge of the Procore domain which enables us to construct rate limits that make sense for Procore specifically, as opposed to an off-the-shelf rate limiting solution. Quota Minder also has the concept of “tiered buckets” which allow for several different types of rate limits to be counted against a client at any given time. We are then able to enforce both “spikes” and “count” rate limits, which protect against short bursts of traffic as well as more prolonged elevated request rates, respectively.
Quota Minder is also valuable to us because it has an interface for dynamic quota configuration. This enables us to configure quota for individual clients on the fly, meaning that there isn’t a blanket quota applied to every client.
The Quota Minder service is deployed on a single host. This creates a single point of failure. If there are unexpected problems on that host our entire rate limiting service becomes unavailable. Furthermore, any deploys to this service require a downtime because the single host must be brought down and spun up with the new code. In order to address these problems, we started a project to make our service highly available.
We could have deployed multiple Quota Minder instances behind a load balancer. Unfortunately, this wouldn’t work because Quota Minder keeps local state as the quotas are tracked in an in-memory key-value store, ets. This creates a problem for making the service highly available because each individual host would be incrementing quota for clients independently, and the rate limiting would become ineffective.
We could have attempted to solve the problem with local state by sharding different clients’ quotas on many Quota Minder hosts. Unfortunately, this would still not meet the standard for being highly available. Deployments or network interruptions affecting a single or many hosts would result in subsections of clients unable to use the Quota Minder service.
In order to address these problems, we decided to focus on removing state from the Quota Minder by replacing ets with Redis. We could then have a multi node implementation of our rate limiting service.
We also needed to avoid Redis becoming a single point of failure for this service as this would fail to ensure the promise of high availability. Using ElastiCache Redis, Amazon’s Redis as a service offering, the Redis nodes we deploy are also considered highly available through Redis’ own mechanisms. This is all handled by Amazon, allowing us to focus on our application.
Timing Constraint
The most important constraint of Quota Minder is the API call timing. Quota Minder is called on every API request to Procore’s main web app. Here is a diagram explaining this interaction.
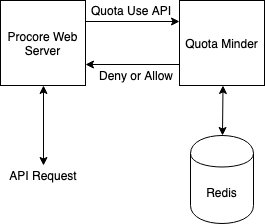
Quota Minder has a strict time limit on its API: if a Procore web server does not complete the entire request to Quota Minder within 15 milliseconds, then the API request is allowed to complete without being checked against the client’s quota.
This presents a problem when reaching out to Redis. We are adding a network round trip and an entirely different service into the critical path of all API requests at Procore. Latencies between Quota Minder and Redis become extremely important, and every effort to limit the amount of times Quota Minder reaches out to Redis must be taken.
Latency Reduction
The main cost in this API call is the network latency between Quota Minder and Redis. The two main latency reduction tactics were:
- Reducing the round trips between Quota Minder and Redis involved in completing an action. Some tactics we used for this are the following:
- Using Redis pipelines we were able to send a batch of commands in one network trip that will be executed in order on the Redis server.
- Choosing different trade-offs in Quota Minder code. The initial incarnation of Quota Minder did not need to be overly concerned about the number of times it needed to communicate to the cache because there was no network round trip involved. With the introduction of Redis and the cost associated with communicating to it, that changed. In our effort to reduce the number of times we needed to talk to Redis, we found opportunities where we could trade cache look-ups for extra processing, resulting in lower overall latency.
- Relocating the primary Redis instance in AWS to the same availability zone as the primary Quota Minder instance.
- Most applications only require being in the same Amazon region to meet their network latency requirements. The latency added in network requests within an Amazon region were unacceptable for the communication between Quota Minder and Redis. A few changes in our Terraform code was required to move both services into the same availability zone (which is actually the same datacenter). This reduces the physical distance the network requests has to travel and cut our network latency roughly in half.
Results
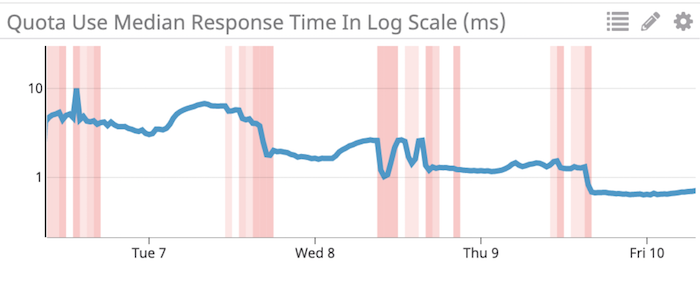
The above screenshot from DataDog shows the time it took for Quota Minder to respond to the “quota use” API from May 6th to May 10th. The blue line represents median Quota Minder API response times in milliseconds. The vertical red stripes represent deploys to production. Over three days, we had 78 different deploys to test out our code and attempt to achieve latency improvements. After each chunk of deploys you can see that we iteratively improved and reduced the latency.
Our first attempt at including Redis in Quota Minder had median API latencies of ~6ms during peak traffic. Through four days of experimentation and iteration, we were able to reduce this median latency to ~0.7ms during peak traffic, an order of magnitude improvement. The maximum API timings were significantly improved as well, from ~10ms to ~3ms, giving us much more breathing room under the 15ms request timeout.
Takeaway: Testing in production can increase quality and velocity
- Code that was pushed to production was not perfect. When the code proved to be correct and valuable through the production test we then went back and cleaned it up.
- The behaviour of our production system was sometimes not at all like we expected or what we planned for. Some examples are the long tail of Redis command timings, where the 99th+ percentile would be 20-100x the median timings. Another is the large spike of API requests we get on the top of every hour, which load tested all of the code we were deploying at a regular interval.
- Testing in production allowed us to avoid the cost of developing robust testing infrastructure to mimic our unpredictable production traffic.
What allowed us to do this safely?
LIMITED BLAST RADIUS
From the beginning Quote Minder was built with strong circuit breaking behavior and a fail-safe design, minimizing the customer impact of our service becoming unavailable or degraded for short periods of time. The system design allows for Quota Minder to be unavailable without meaningfully harming a customer’s experience, creating a limited blast radius.
If Quota Minder doesn’t respond to an API call in 15ms the API call is allowed to complete without being counted against a client’s quota. This means that if Quota Minder became completely unresponsive (like it did a few times during testing) then the maximum latency incurred on any API request would be 15 ms and clients would not be denied in their API requests. This allowed us to have confidence that any disastrous deploys to production would not ripple to any other parts of our system.
QUICK DEPLOYS AND REVERTS
A critical safeguard was the speed of our deploys and reverts. Quota Minder can be deployed in about 5 seconds. Problems in production were not long lived and had a limited customer impact.
The largest factor in reducing deploy times was using a thinner docker image, alpine-elixir. There are also security and performance benefits of using alpine as a base image. More information and benchmarks can be found online.
ROBUST MONITORING AND ALERTING
We invested heavily in making this service easy to observe and debug in production through a robust set of performance and reliability metrics and structured logging. Over time, we have built up an intuition from these metrics and monitoring of our services. This made testing in production valuable because any shifts in our key metrics could be easily identified and understood, informing our decision to keep or re-work any code.
There are a few “golden signals” which do not require full context to understand if a deploy was healthy or not. For Quota Minder, these would be API request times, 500 response counts, and client timeouts. These golden signals can be used in the future for automated rollbacks.
Wrapping Up
Ultimately, we were successful in making Quota Minder a highly available service. We were able to achieve these goals and reduce latency to an acceptable level by making use of testing in production. We believe that testing in production can enable high velocity development through rapid experimentation. In order to do this safely and with minimal customer impact, we outlined a few best practices to implement before attempting tests in production.
We are looking at implementing further patterns to continue iterating at high velocity with minimal risk. Some things on our radar are blue-green deploys, canary releases, and automated rollbacks as we continue to seek fast and stable iterations.
If you see yourself enjoying solving these types of problems, check out our engineering jobs page for career opportunities at Procore.